:quality(80)/p7i.vogel.de/wcms/e6/4f/e64f82834f3478fd69dd95dd20afacb0/0131498780v1.jpeg "René Brugger, Präsident SwissT.net: «. Unternehmen suchen nicht einfach nach 'mehr Technik', sondern nach Lösungen, die Kosten senken, Prozesse stabilisieren, Qualität sichern und die Wettbewerbsfähigkeit erhöhen. Automation ist dabei kein Luxus, sondern eine betriebswirtschaftliche Notwendigkeit.» (Bild: SwissT.net)")
:quality(80)/p7i.vogel.de/wcms/44/7a/447a49a9c3a20a8bf9535c1fe9a2b75f/0131890096v2.jpeg "Der KI-Supercomputer von Phoeniqs ist für die Ausführung, das Training und die Orchestrierung komplexer KI-Modelle, wie Large Language Models, im industriellen Umfeld optimiert. Er kombiniert High-Performance-Computing mit kompromissloser Datensicherheit. (Bild: Phoeniqs)")
:quality(80)/p7i.vogel.de/wcms/c3/41/c341ab4f69f650644ae35309eecfb064/0131898421v2.jpeg "Eindrücke von der Embedded Computing Conference am 2. Juni 2026 an der ZHAW in Winterthur. (Bild: Anne Richter, VCG)")
:quality(80)/p7i.vogel.de/wcms/e8/f5/e8f5cce446e0c5d3346e6bd68664e6eb/0131807410v1.jpeg "Digitale Exponate auf der AMB: Ausstellende Unternehmen machen ihre Lösungen für die moderne Metallzerspanung unmittelbar erlebbar. (Bild: Thomas Wagner)")
:quality(80)/p7i.vogel.de/wcms/58/40/58401bca8737eee4a8f38f5bf06e3b75/0131952180v2.jpeg "Die neuen elektromagnetischen Scheibenbremsen der Ringspann-Baureihe DA sind ausgelegt für den Einsatz in Stahl-, Hafen- und Kraftwerkskranen oder grossen Förder-, Schüttgut- und Zerkleinerungsanlagen. (Bild: Ringspann)")
:quality(80)/p7i.vogel.de/wcms/8c/e3/8ce3e2eb3bb2b7713bc7d560faeb64ab/0131907143v1.jpeg "Siemens hat mit XLad die sogenannte Kontaktplanprogrammierung als erste grafische Programmiersprache in Simatic AX Logic Control Engineering eingeführt (Bild: Siemens)")
:quality(80)/p7i.vogel.de/wcms/09/9b/099bbedba2b83aeb7b3db5eee21aa26f/0131047054v2.jpeg "(Bild: Beckhoff)")
:quality(80)/p7i.vogel.de/wcms/be/77/be77edf1989ef5010da7db8fb740c403/0131899287v2.jpeg "(Bild: Codesys)")
:quality(80)/p7i.vogel.de/wcms/38/1f/381f6a1fb80ea58b816f6b058d1ae6b4/0131963607v1.jpeg "(Bild: Schurter)")
:quality(80)/p7i.vogel.de/wcms/08/e9/08e9c6315f39ea96800a555c7da32fd4/0131946183v1.jpeg "Ziel des All2GaN ist es, Energieverbrauch und CO₂ Emissionen durch modulare, leicht integrierbare GaN Leistungshalbleiter zu reduzieren. (Bild: Fraunhofer IZM / Volker Mai)")
:quality(80)/p7i.vogel.de/wcms/5f/e5/5fe57ad1a595d139585e9db954f424ea/0131268744v2.jpeg "(Bild: Relmatic)")
:quality(80)/p7i.vogel.de/wcms/39/d9/39d969c361f18ca48f955129d1fcfa65/0131889864v1.jpeg "Das Metracal CM ist der optimale Partner für anspruchsvolle Mess- und Kalibrieraufgaben in Industrieanlagen und deckt alle gängigen Signalarten der Prozess- und Labormesstechnik ab. (Bild: Gossen Metrawatt )")
:quality(80)/p7i.vogel.de/wcms/27/5d/275dac6ec6fe9074b46595f4280d7bdb/0131055501v2.jpeg "Mit Surfacecontrol Automotive bietet Micro-Epsilon ein roboterbasiertes Inspektionssystem zur vollautomatischen Oberflächenprüfung von Roh-Karosserien (Body-in-White). (Bild: Micro-Epsilon)")
:quality(80)/p7i.vogel.de/wcms/7f/3c/7f3c27423a54e1a5bc9b2e91cabf96fe/0131837262v1.jpeg "Der QPS201 wird als zusätzlicher Kontrollschritt eingesetzt, um zu überprüfen, ob in Gewahrsam genommene Personen verbotene Gegenstände verbergen. (Bild: Rohde & Schwarz)")
:quality(80)/p7i.vogel.de/wcms/8d/14/8d14d609b61c50013882d50c330ac1cf/0131737087v1.jpeg "Die neuen NCFx Pro Fügemodule Typ 2164A von Kistler sind dank Telemetrie mit kabellosen Dehnmessstreifen DMS- oder piezoelektrischen-Kraftsensoren ausgestattet direkt in der Werkzeugaufnahme beziehungsweise am Stössel. (Bild: Kistler Gruppe)")
:quality(80)/p7i.vogel.de/wcms/9e/ad/9ead1b5718e3b0e9bc182e659b656f48/0131948103v1.jpeg "Mazda will die Entwicklung der Software-Defined Vehicles beschleunigen. Dafür wird Mazda die Application-Lifecycle-Management-Lösung (ALM) PTC Codebeamer einsetzen. (Bild: Mazda)")
:quality(80)/p7i.vogel.de/wcms/e4/f0/e4f0b741853ebe17f69195eff567738b/0131850457v1.jpeg "(Bild: Neurawork AI / Leonardo.ai / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/d1/6f/d16fcb0caeedef3714e6951a8a89eab5/0131869454v2.jpeg "Digitalisierung und Beratung in der Prozessindustrie sichern nachhaltige Wettbewerbsfähigkeit. (Bild: Endress+Hauser)")
:quality(80)/p7i.vogel.de/wcms/30/c9/30c99b40ba542942e56b34124200bfa8/0131916708v1.jpeg "Perowskit-Photovoltaik industriell fertigen: Forscher entwickeln skalierbares Verfahren. (Bild: Alexander Diercks, KIT)")
:quality(80)/p7i.vogel.de/wcms/ab/d6/abd6387e8f853f78caea07eba76b2fdf/0131846531v1.jpeg "Isabella stellt einen bedeutenden Schritt hin zu einer kompakten optischen Atomuhr dar. Der studentische Mitarbeiter Carlos Gomez misst dafür am Fraunhofer IZM die optischen Eigenschaften eines Glas-basierten photonischen Chips. (Bild: Fraunhofer IZM)")
:quality(80)/p7i.vogel.de/wcms/5c/2c/5c2cc2bbfb10dd033712847e2ac0505a/0131072599v2.jpeg "Sensoren an den Fussgelenken der Einsatzkräfte. (Bild: IFG - TU Graz)")
:quality(80)/p7i.vogel.de/wcms/59/ba/59ba351d6ec50128292f0153ab7bce38/0124040720v4.jpeg "(Bild: Gribi Hydraulics)")
:quality(80)/p7i.vogel.de/wcms/aa/76/aa76ed03b7a0018cc51bef73a529269c/0124205347v2.jpeg "Die Dialysefilter werden im Dreischicht-Betrieb rund um die Uhr in einem automatischen Prüfstand unter Reinraumbedingungen getestet. (Bild: Bürkert)")
:quality(80)/p7i.vogel.de/wcms/1a/a0/1aa01f35aaecf1d5fc635c4ab1d93a61/0120564266v2.jpeg "Die kompakte Baugruppe besteht aus drei Ventilen, einem Drucksensor, einer Kondensatfalle und einer Membranpumpe, die in einer Kammer Überdruck und in der zweiten Kammer Unterdruck erzeugt. Zwischen den beiden Kammern schaltet dann ein Ventil dynamisch um, was eine Schlauchrollen-Pumpe überflüssig macht. (Bild: Fresenius Medical Care)")
:quality(80)/p7i.vogel.de/wcms/52/85/528512fe3a56c6f8d450199fc4bfbf0b/0119296574v2.jpeg "Ultraschall-Clamp-on-Durchflussmessgeräte Proline Prosonic Flow W 400 und P 500 – eingriffsfrei und einfach zu installieren – keine Prozessunterbrechung – wartungsfrei. (Bild: Endress+Hauser)")
:quality(80)/p7i.vogel.de/wcms/82/e6/82e6d70e9d84f25c586d579afe6adf1d/0130060130v2.jpeg "Sick Nova Intelligent Inspection ermöglicht skalierbare KI gestützte Bildverarbeitung für moderne Qualitäts und Automatisierungsaufgaben. (Bild: Sick)")
:quality(80)/p7i.vogel.de/wcms/3e/cf/3ecfea7fe5091e452093099a66c2cad2/0130248024v2.jpeg "Die Stärke von Elcase ist massgeschneiderte Bearbeitung von Schaltschränken und Elektrogehäusen nach kundenspezifischen Wünschen. (Bild: Elcase)")
:quality(80)/p7i.vogel.de/wcms/94/a6/94a65981a49534064cf8acd2e1551ce1/0130059180v2.jpeg "Das IO-Link Safety-Paket aus Master, Sensoren sowie Feldgeräten und passendem Zubehör von Pilz unterstützt mit Blick auf das Internet der Dinge IIoT vernetzte Maschinen und Anlagen herstellerungebunden bis auf die Sensor- bzw. Feldebene. (Bild: Pilz)")
:quality(80)/p7i.vogel.de/wcms/c8/55/c8557098bfd8d49279bd39e3a1516510/0129888420v2.jpeg "IO-Link-Topologie auf dem Förderband – von der Stromversorgung bis zu Condition-Monitoring-Sensoren. (Bild: Balluff)")
Maschinelles Lernen Maschinelles Lernen — Gegenwart und Zukunft
Um Zielkunden besser bedienen zu können als die Konkurrenten, suchen Embedded Design Teams schon heute nach neuen Technologien wie Machine Learning und Deep Learning.
Anbieter zum Thema
:fill(fff,0)/images.vogel.de/vogelonline/companyimg/67000/67003/65.jpg "Logo.jpg ()")
Mit Machine Learning (ML) und Deep Learning (DL) lassen sich von diesen Teams komplexe Modelle von einem oder mehreren Systemen mithilfe eines datengesteuerten Ansatzes erstellen. Statt physikalisch basierte Modelle zur Beschreibung des Systemverhaltens zu verwenden, leiten ML- und DL-Algorithmen das Modell eines Systems aus Daten ab. Herkömmliche ML-Algorithmen sind nützlich, wenn die zu verarbeitende Datenmenge relativ klein und die Komplexität des Problems gering ist. Aber was ist bei grösseren Problemen mit viel mehr Daten wie dem autonomen Fahrzeug? Diese Herausforderung erfordert DL-Techniken. Dieser Artikel zeigt auf, wie diese neue Technologie in die nächste Ära eines Steuerungs-Designs und das Industrial Internet of Things (IIoT) drängen wird.
Zustandserfassung unterstützt Fehleranalyse
Als Erstes wird eine Anwendung der ML-Technologie für die zustandsorientierte Überwachung von Industrie-Anlagen beleuchtet. ML hat dabei geholfen, zustandsbasierte Überwachungsanwendungen von der Ära der reaktiven und präventiven Wartung zu einer Ära der vorbeugenden Instandhaltung zu überführen. Diese Techniken werden verwendet, um anomales Verhalten zu erkennen, Probleme zu diagnostizieren und bis zu einem gewissen Grad die Restnutzungsdauer von Industrieanlagen wie Motoren, Pumpen und Turbinen zu prognostizieren. Der Ablauf für die Entwicklung und Bereitstellung von Modellen auf Basis von ML ist im Bild 1 dargestellt.
Wie wird dieser Workflow genutzt, um den Zustand eines Motors zu überwachen? Die Daten werden von unterschiedlichen Sensoren wie Beschleunigungssensoren, Thermo-Elementen und Stromwandlern gesammelt, die direkt am Motor angebracht sind. Das Feature-Engineering besteht in der Regel aus zwei Teilen: Feature-Extraktion und Feature-Reduktion. Die Merkmals-Extraktion wird verwendet, um aus den Rohdaten Informationen abzuleiten, die notwendig sind, um den Zustand der Anlage zu erfassen. Beispielsweise enthält das Frequenzspektrum des Stromsignals vom Motor Informationen, die zur Erkennung von Fehlern verwendet werden können, wie in Abbildung 2 dargestellt. Die durchschnittliche Amplitude über verschiedene Frequenzbereiche dient als Kenngrösse, die aus dem Stromsignal extrahiert wird. Messungen, die aus mehreren Sensoren extrahiert wurden, enthalten redundante Informationen. Eine Methode zur Reduzierung von Eigenschaften, wie z. B. die Hauptkomponentenanalyse (Principal Component Analysis, PCA), kann dazu genutzt werden, die Anzahl der Merkmale zu reduzieren, die letztlich für die Erstellung eines Modells verwendet werden. Die Reduzierung der Anzahl der Features reduziert die Komplexität des zu verwendenden ML-Modells. Die reduzierte Menge an Merkmalen wird als Vektor (oder Array) dargestellt und in den ML-Algorithmus eingegeben, der im Schritt der Modellerstellung verwendet wird. Die Modellerstellung und -validierung ist ein iterativer Prozess, bei dem der Anwender mit mehreren ML-Algorithmen experimentieren und denjenigen auswählen kann, der am besten für seine Anwendung geeignet ist.
Intelligente Algorithmen erkennen Anomalitäten
Ein unbewachter ML-Algorithmus wie das Gausssche Mischungsmodell (GMM) lässt sich verwenden, um das normale Verhalten des Motors zu modellieren und zu ermitteln, wenn der Motor anfängt, von seinem Ausgangswert abzuweichen. Nicht überwachte Methoden sind bestens geeignet, um versteckte Muster in den Daten aufzudecken, ohne dass die Daten markiert werden müssen. Während unbeaufsichtigte Techniken zur Erkennung von Anomalien des Motors eingesetzt werden können, sind überwachte Algorithmen erforderlich, um die Ursache der Anomalie zu ermitteln. In überwachten Methoden wird der Algorithmus mit Paaren der Eingangsdaten und der gewünschten Ausgabe dargestellt. Diese Daten werden als markierte Daten bezeichnet. Der Algorithmus lernt die Funktionsweise, welche die Eingänge auf die Ausgänge abbildet. Die Daten, die für das Lernen des ML-Algorithmus verwendet werden, umfassen Merkmale, die unter normalen und fehlerhaften Bedingungen extrahiert wurden. Die Merkmale sind durch ein Etikett, das den Zustand des Motors kennzeichnet, eindeutig gekennzeichnet. Support-Vektor-Maschinen (SVM), logistische Regression und künstliche neuronale Netze sind häufig verwendete überwachte ML-Algorithmen. Eine Herausforderung bei traditionellen ML-Techniken ist die Feature-Extraktion. Es handelt sich um einen sensiblen Prozess, der das Wissen eines Domain-Experten voraussetzt und in der Regel der Schwachpunkt im ML-Workflow ist. DL-Algorithmen haben in letzter Zeit an Popularität gewonnen, weil sie die Notwendigkeit des Feature-Engineering-Schrittes eliminieren. Die von den Sensoren erfassten Rohdaten können direkt in die DL-Algorithmen eingegeben werden (siehe Bild 4). DL-Algorithmen basieren auf künstlichen neuronalen Netzen. Die Lernalgorithmen für künstliche neuronale Netze orientieren sich an den Struktur- und Funktionsaspekten biologischer neuronaler Netze. Diese Algorithmen sind in Form einer Gruppierung von Rechenknoten (künstliche Neuronen) strukturiert, die in Schichten organisiert sind. Die erste Schicht wird als Eingangsschicht bezeichnet, die mit dem Eingangssignal oder den Daten verbunden ist. Die letzte Schicht ist die Ausgabeschicht, und die Neuronen in dieser Schicht liefern die endgültige Vorhersage oder Entscheidung. Zwischen der Eingangs- und der Ausgangsschicht befinden sich eine oder mehrere ausgeblendete Schichten (Abbildung 5). Die Ausgänge einer Schicht sind durch gewichtete Beziehungen mit den Knoten der nächsten Schicht verbunden. Ein Netzwerk erlernt ein Mapping zwischen Ein- und Ausgang, indem es diese Gewichtungen modifiziert. Durch die Verwendung mehrerer nicht sichtbarer Schichten lernen DL-Algorithmen die Eigenschaften, die aus den Eingabedaten extrahiert werden, ohne dass die Eigenschaften explizit in den Lern-Algorithmus eingegeben werden müssen. Dies wird als Feature-Learning bezeichnet. DL verzeichnet in jüngster Zeit Erfolge bei IIoT-Anwendungen, vor allem wegen der zunehmenden Entwicklung technologischer Komponenten, wie z. B. höhere Rechenleistung in der Hardware, grosse Datenbestände mit beschrifteten Trainingsdaten, Durchbrüche bei Lernalgorithmen und Netzwerkinitialisierung sowie die Verfügbarkeit von Open-Source-Software-Frameworks. Nachfolgend einige grundsätzliche Überlegungen zur Auslegung von Anlagen mit dieser Technologie. Topologien-DL ist ein sich ständig weiterentwickelndes Feld, und zahlreiche Netzwerktopologien sind derzeit im Einsatz. Einige dieser Netzwerke, die aussichtsreich für die Steuerung und Überwachung von IIoT-Anwendungen sind, werden im Folgenden diskutiert:
- Deep fully connected neuronale Netze sind vollständig verbundene künstliche neuronale Netze mit vielen verborgenen Schichten (also tief). Diese Netzwerke sind ausgezeichnete Approximatoren und eignen sich z. B. für den Einsatz in der Leistungselektronik. Um einen Controller mit tiefen Netzwerken zu bauen, wird das Simulationsmodell des zu steuernden Systems zur Generierung der Trainingsdaten verwendet. Damit lassen sich Zustände (Randbedingungen) erforschen, die mit herkömmlichen Methoden nur schwer zu beherrschen sind.
- Konvolutionäre neuronale Netze sind so konzipiert, dass sie die Vorteile der zweidimensionalen Struktur von Eingangssignalen wie Eingangsbildern oder Sprachsignalen nutzen. Ein Konvolutionsnetz besteht aus einer oder mehreren Konvolutionsschichten (Filterschichten), gefolgt von einem vollständig verbundenen, mehrschichtigen neuronalen Netzwerk. Diese Netzwerke sind erfolgreich bei Problemen wie der Fehlererkennung in Bildern und der Objekterkennung. Sie dienen dem Motiv-Verständnis in modernen Fahrerassistenz-Systemen.
- Wiederkehrende neuronale Netze (WNN) basieren auf Algorithmen, die sequenzielle (oder historische) Informationen nutzen, um Prognosen zu erstellen. Diese Netzwerke eignen sich gut für die zeitliche Zeitreihenanalyse. Ein traditionelles neuronales Netzwerk geht davon aus, dass alle Eingänge (und Ausgänge) unabhängig voneinander in der Zeit oder Reihenfolge des Eintreffens sind. WNNs zeichnen Zustandsinformationen auf. Diese speichern Informationen über die Vergangenheit und verwenden die bisher berechneten Ergebnisse für die nächste Vorhersage. In IIoT-Anwendungen sind WNNs gut geeignet, um historisches Verhalten zu erlernen und damit zukünftige Ereignisse wie die Restnutzungsdauer (RUL) eines Assets vorherzusagen. Für diese Art von Anwendungen eignet sich das Long-Short-Term-Memory-Netzwerk (LSTM-Netzwerk).
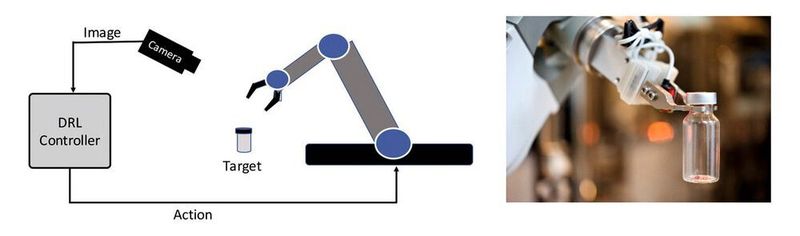
- Deep Reinforcement Learning (DRL) eignet sich gut für die Entwicklung adaptiver Regelsysteme, die in komplexen dynamischen Umgebungen arbeiten. Denken wir an die Steuerung von Robotern, die im Lagerbetrieb eingesetzt werden, wo sich die Roboter dynamisch an neue Anforderungen anpassen sollen. Die lernbasierten Controller lernen eine Aufgabe durch die Informationen, die sie für die Durchführung einer Aktion erhalten und die sie dem Ziel näherbringt. Beispielsweise erhält die Steuerung von einer Kamera ein Bild, das die aktuelle Position eines Roboterarms anzeigt und anhand der Informationen im Bild lernt, wie man den Arm näher an das Ziel heranführt. Die DL-basierte Steuerung kann mithilfe eines Robotersimulators oder durch Beobachtung des realen Roboters in Aktion trainiert werden.
Deep Learning auf unterschiedlichen Stufen
Training: Deep Neuronale Netze erfordern grosse Mengen an Trainingsdaten, die vorzugsweise Daten aus allen verschiedenen Zuständen oder Bedingungen enthalten, die das Netzwerk lernen muss. Für die meisten Anwendungen stammen die verfügbaren Daten überwiegend aus dem normalen Betriebszustand eines Systems mit einer kurzen Stichprobe von Daten aus anderen Zuständen. Die Datenerweiterung ist eine Technik zur Verbesserung dieses Datenungleichgewichts, bei der man mit dem vorhandenen kleinen Sample-Set beginnen und durch Umwandlung der Daten zusätzliche künstliche Versionen erstellen kann. Zusätzlich besteht die Möglichkeit, mithilfe von Simulationsmodellen des Systems Trainingsdaten zu erzeugen. Eine weitere Herausforderung besteht darin, dass es problematisch ist, die grossen Datenmengen zu sammeln, die für die Qualifizierung dieser Netze erforderlich sind. Das Transfer-Lernen ist ein Ansatz, mit dem man dieses Problem mildern kann. Beim Transfer-Learning wird mit einem vorbereiteten neuronalen Netzwerk (die meisten DL-Software-Frameworks bieten ausgereifte Modelle, die man herunterladen kann) begonnen und mit Daten aus der Anwendung im weiteren Verlauf optimiert. Hardware-Schulung in tiefen Netzwerken stellt enorme Anforderungen an die Datenverarbeitung. GPUs haben sich als primäre Alternative für das Training tiefer Netzwerke herausgestellt.
Grafikprozessoren sind attraktiv und aufgrund der hohen Rechenleistung, des grossen Speichers, der hohen Speicherbandbreite und der Auswahl an Programmierwerkzeugen nahezu eine Notwendigkeit für das Training. FPGAs sind zudem gute Voraussetzungen für den Einsatz von qualifizierten Netzwerken. FPGAs sorgen für niedrigere Latenzzeiten, bessere Energieeffizienz und Determinismus, speziell für den Einsatz dieser Netzwerke auf Embedded Devices für Steuerungssysteme, die in einem engen Regelkreis mit I/O arbeiten. Software: Ein Grund für die rasche Akzeptanz und den Erfolg von DL ist die Verfügbarkeit ausgereifter Software-Frameworks. Einige der Gebräuchlichsten sind TensorFlow, Caffe, Keras, Keras und CNTK. Diese Frameworks unterstützen verschiedene Betriebssysteme wie Windows und Linux sowie Programmiersprachen wie Python und C++. Die meisten dieser Frameworks verfügen über Unterstützung oder Beispiele für die Implementierung der neuesten DL-Netzwerke. Sie ermöglichen auch das Lernen auf GPUs.
DL ist eine spannende neue Richtung der künstlichen Intelligenz und eine vielversprechende Technologie zur Lösung von Problemstellungen der nächsten Generation in der industriellen Steuerungsentwicklung. Eine einfache Möglichkeit, mit DL zu beginnen, besteht darin, eines der oben genannten Open-Source-Frameworks zu downloaden und mit den Tutorial-Beispielen zu experimentieren. Am besten startet man mit einem Beispiel, das ähnlich der Anwendung ist und nutzt Transfer-Learning, um schnell einsatzbereit zu sein.
(ID:47712150)
:quality(80)/p7i.vogel.de/wcms/33/0d/330df2ff5201c6662cc0ea7febb0931c/0129113088v2.jpeg "Bild 5: Mit Künstlicher Intelligenz lässt sich die Präzision optischer Distanzsensoren auf ein neues Niveau heben. Beispielsweise beim Einsatz in der Intralogistik. (Bild: Leuze)")
:quality(80)/p7i.vogel.de/wcms/f1/6d/f16d23a863ed9e795fd9d0f276c5b29b/0105840490v2.jpeg "0105840490 (Bild: iStock / PhonlamaiPhoto)")